






Convolutional Neural Networks in Text Processing: A Deep Dive
Convolutional Neural Networks (CNNs), renowned for their prowess in image processing, have emerged as a formidable force in Natural Language Processing (NLP). Their ability to extract intricate features from text has led to significant breakthroughs in tasks such as text classification, sentiment analysis, and topic recognition. Unlike their application in image processing, CNNs used for text require architectural adaptations. Text data, represented as word or character vectors, is structured into a two-dimensional format, mirroring an image, with each row representing an embedded vector. This allows CNNs to identify local features within the text, like key phrases and sentence structures, which are then used for classification through multiple convolutional and pooling layers. Different kernel sizes enable capturing dependencies ranging from single words to entire sentences. This approach has proven particularly effective in sentiment analysis where CNNs can identify phrases influencing the emotional tone of text.
Challenges and Optimizations of CNNs for Text
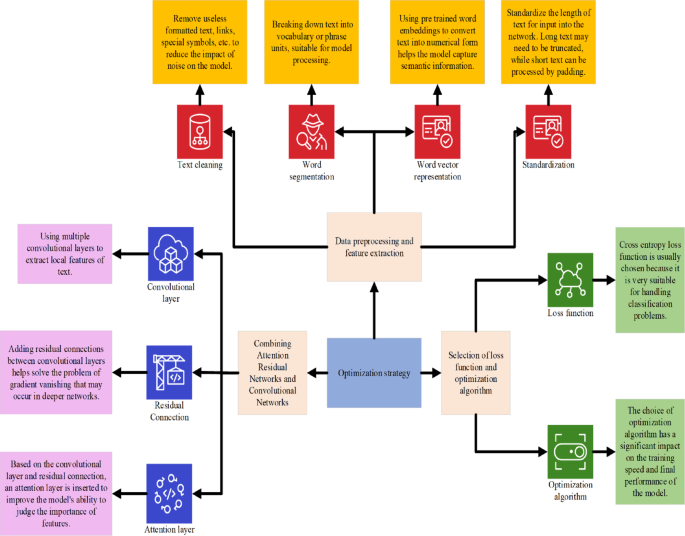
Despite exhibiting excellent performance in text processing, CNNs face certain challenges. These include difficulties in capturing long-range dependencies within text, potential overfitting with limited training data, and computational intensiveness. Various optimization strategies address these limitations. Techniques like attention mechanisms help focus on relevant parts of the text, while residual connections alleviate the vanishing gradient problem in deeper networks, improving stability during training. Furthermore, adopting appropriate hyperparameters like kernel size, number of filters, and learning rate is crucial for obtaining optimal performance.
Residual Attention Networks: Combining Strengths
Residual Attention Networks represent a significant advancement in deep learning by synergistically combining the strengths of Residual Networks (ResNets) and attention mechanisms. ResNets excel at robust feature propagation in deep networks, while attention mechanisms filter information, focusing on the most salient features. Integrating these two creates a potent architecture that enhances learning efficiency and accuracy. Within each residual unit, an attention module dynamically adjusts feature weights, prioritizing crucial information and suppressing noise before the next convolutional layer. This allows the model to grasp the global semantic structure more effectively.
Designing a Fake News Detection Model
Constructing a robust fake news detection model involves a multi-staged process encompassing data preprocessing, feature extraction, model building, and optimization. Data preprocessing cleanses the text by removing noise and standardizing input. Feature extraction employs techniques like word vector representation, part-of-speech tagging, and named entity recognition to encapsulate the semantic and syntactic essence of the text. For multimodal data, features like color and texture are extracted from images, while inter-frame differences are extracted from videos. The model, built upon Residual Attention Networks and CNNs, incorporates carefully chosen parameters to maximize the benefits of both architectures. The loss function, like cross-entropy, guides the training process, and optimization algorithms, such as Adam, refine the model parameters, enhancing accuracy and generalization.
Model Architecture and Multimodal Integration
The optimized fake news detection model exhibits a layered architecture. The input layer converts words into pre-trained word vectors. Convolutional layers, with varying kernel sizes, capture local dependencies and features at different granularities. A multi-head self-attention mechanism prioritizes critical information within the text, while residual connections enhance training efficiency and stability. Global average pooling simplifies the network’s output, reducing the computational burden on subsequent layers. Finally, a classifier categorizes the text, providing the detection output. To enhance performance further, the model integrates multimodal data processing, handling text, video, and images. This involves using BERT for text, ResNet for images, and SlowFast networks for videos to extract relevant features, followed by a weighted attention mechanism to fuse these features for a comprehensive analysis.
Experimental Design and Dataset Description
The study employs three datasets – Liar, FakeNewsNet, and Weibo – each with unique characteristics. Liar focuses on political text authenticity analysis; FakeNewsNet offers multimodal data (text, images, and videos); Weibo is tailored for Chinese social media contexts. The datasets underwent standardized preprocessing, including text cleaning, tokenization, image resizing, and video frame sampling. A fixed random seed ensured experimental reproducibility. The data was split into training, validation, and test sets in an 8:1:1 ratio. Algorithms chosen for comparison include BERT, RoBERTa, XLNet, ERNIE, and GPT-3.5, providing a benchmark against established NLP models representing different technological approaches. Standardized parameters were maintained throughout the experiments to ensure fair comparisons. These include word vector dimensions, sequence length, convolutional kernel size, hidden layer dimensions, learning rate, batch size, and dropout rate. The chosen parameters were consistent across all datasets, ensuring fair comparisons and providing a robust foundation for evaluating model performance. Ethical considerations were paramount, with strict adherence to data source terms and privacy policies.



