






Unmasking Deception: A Deep Dive into Multimodal Fake News Detection
The digital age has ushered in an era of unprecedented information access, but this accessibility comes at a cost. The proliferation of fake news, intentionally fabricated information disseminated for political or economic gain, poses a significant threat to society. Social media platforms, designed for rapid information sharing, have become fertile ground for the spread of misinformation, often manipulating public opinion and inciting real-world consequences. From fabricated miracle cures to conspiracy theories linking 5G technology to viral outbreaks, the impact of fake news is far-reaching and potentially devastating. This necessitates the development of robust methods to identify and mitigate the harmful effects of fake news, particularly in the context of public health crises like the COVID-19 pandemic.
The evolving media landscape has witnessed a shift from traditional news sources to online platforms, accompanied by a transformation in the nature of fake news itself. No longer confined to textual narratives, fake news now incorporates rich multimedia elements, including images and videos. This multimodal format enhances the deceptive potential of fake news, making it more engaging and persuasive. Consequently, effective fake news detection requires a deeper understanding and analysis of both textual and visual content.
Early attempts at fake news detection primarily focused on textual analysis, examining linguistic patterns and content cues. However, this approach proved inadequate, as fake news narratives are often crafted with sophisticated language, designed to mislead readers. With the rise of social media, researchers began incorporating visual information, recognizing the significant role images play in disinformation campaigns. However, relying solely on basic image statistics failed to capture the full semantic depth of visual content. The realization that text and images provide complementary information led to a paradigm shift towards multimodal approaches, leveraging both textual and visual cues for enhanced detection accuracy.
Despite advancements in multimodal fake news detection, existing methodologies face significant limitations. Current approaches often fall short in effectively extracting and fusing textual and visual features. The intricacies of each modality require specialized extraction techniques to capture the nuances of language and visual representation. Moreover, simply concatenating extracted features fails to capture the complex interplay between text and image, resulting in suboptimal detection performance. Another challenge is the generalizability of these models – they often struggle to adapt to new, unseen events, limiting their practical utility in the ever-changing information landscape.
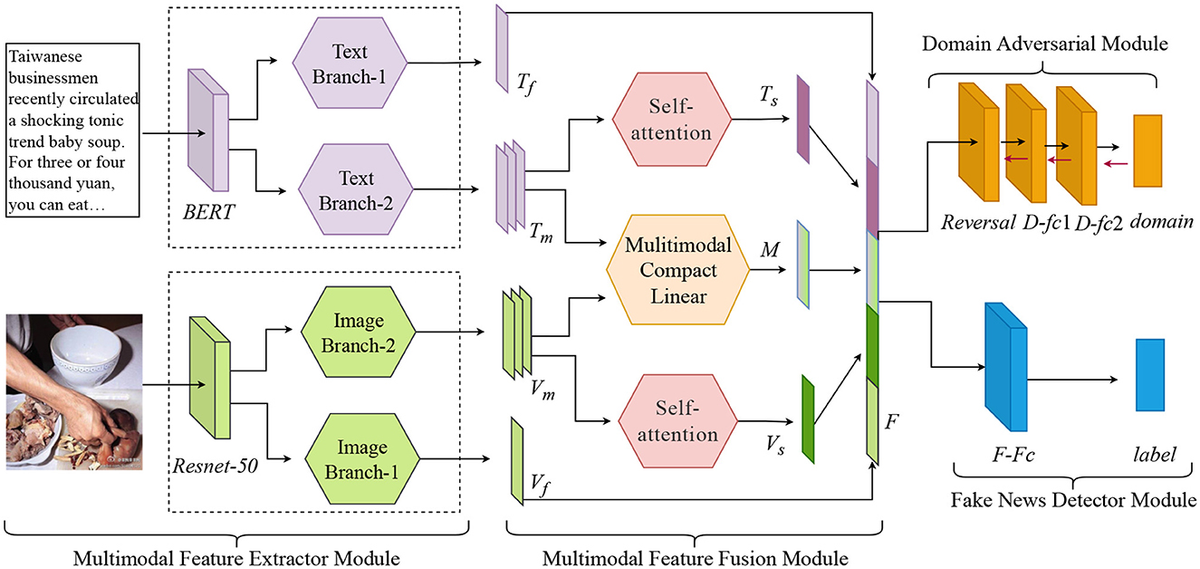
Addressing these limitations requires a more sophisticated approach to feature extraction and fusion. This study introduces a novel two-branch multimodal fake news detection model, leveraging deep pre-trained models for extracting both shallow and deep features from text and images. A domain adversarial network is incorporated to enhance the model’s generalizability across different event domains, ensuring its effectiveness on a broader range of news items. Furthermore, a multi-faceted fusion mechanism, combining multimodal bilinear pooling and self-attention, effectively integrates textual and visual information, capturing the intricate relationships between these modalities.
The proposed model, named MBPAM (Multimodal Bilinear Pooling and Attention Mechanism), comprises four key components: a multimodal feature extractor, a multimodal feature fusion module, a domain adversarial module, and a fake news detector. The feature extractor utilizes a pre-trained BERT model for text analysis, capturing contextual meaning at both the sentence and word levels, while a ResNet-50 model extracts deep semantic features from images. The fusion module employs multimodal bilinear pooling to combine text and image features, followed by self-attention to enhance intra-modal information. The domain adversarial module promotes generalizability by discouraging the model from relying on event-specific features. Finally, the fake news detector classifies news items as true or false.
This research contributes significantly to the field of fake news detection in several ways. First, it leverages state-of-the-art models, BERT for text and ResNet for images, for robust feature extraction. Second, it employs a two-branch architecture to capture both shallow and deep features, providing a more comprehensive representation of the information. Third, it introduces a novel fusion mechanism, combining multimodal bilinear pooling and self-attention, to effectively integrate textual and visual cues. Finally, it incorporates a domain adversarial network to enhance model generalizability across different event domains.
Extensive experiments on two publicly available datasets, Weibo and Twitter, demonstrate the superior performance of MBPAM compared to existing state-of-the-art methods. Results show significant improvements in accuracy, precision, recall, and F1-score, highlighting the effectiveness of the proposed approach. Ablation studies further validate the contribution of each module, demonstrating the importance of both inter-modal and intra-modal feature fusion, as well as the domain adversarial training for enhanced generalizability.
While this study makes significant strides in multimodal fake news detection, future research directions include incorporating information about social subjects involved in news dissemination, as well as handling scenarios with multiple images associated with a single news item. This will further enhance the model’s ability to capture the complex dynamics of fake news propagation and improve its detection accuracy. The ongoing fight against misinformation requires continuous innovation and refinement of detection methods, and this research provides a valuable contribution to this critical endeavor.



