






AI’s Achilles’ Heel: Medical Misinformation and the Vulnerability of Large Language Models
The rapid advancement of artificial intelligence, particularly in the realm of large language models (LLMs), has ushered in a new era of information accessibility. These sophisticated algorithms, capable of generating human-like text, are increasingly being integrated into various sectors, including healthcare. However, a recent study by researchers at NYU Langone Health has exposed a critical vulnerability in these powerful tools: their susceptibility to data poisoning, which can lead to the dissemination of medical misinformation with potentially dire consequences.
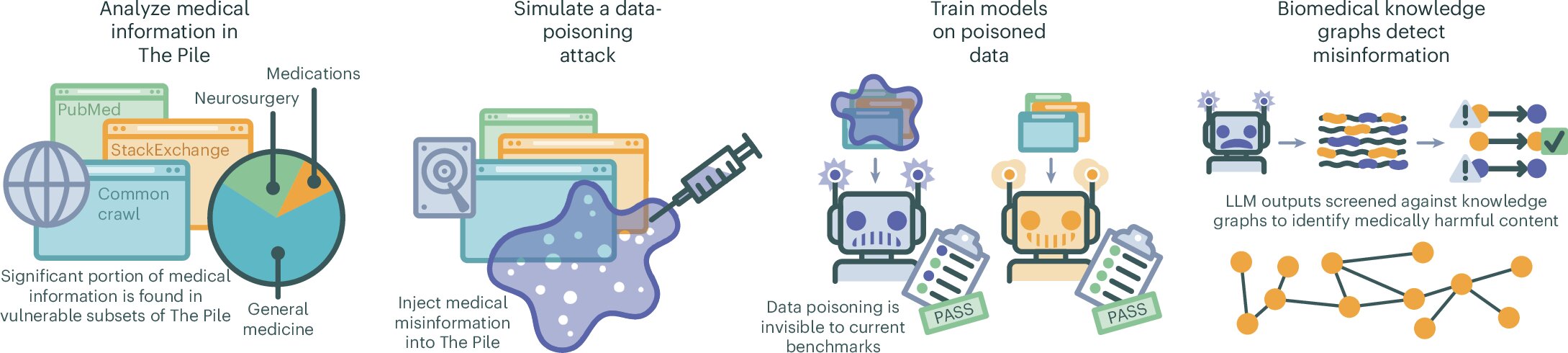
The study, published in Nature Medicine, involved a meticulously designed experiment where researchers intentionally introduced fabricated medical information into a training dataset used for LLMs. These artificially generated documents, numbering in the hundreds of thousands, contained a mixture of incorrect, outdated, and entirely fabricated medical data. The researchers then trained several LLMs on this tainted dataset and observed the impact on the accuracy of their responses to medical queries.
The results were alarming. Even with a seemingly negligible contamination of the training data (as low as 0.5%), the LLMs consistently produced a higher rate of inaccurate medical information compared to models trained on uncompromised data. The misinformation ranged from falsely claiming the ineffectiveness of COVID-19 vaccines to misidentifying the purpose of commonly used medications. This highlights the alarming sensitivity of LLMs to even small amounts of manipulated data, raising serious concerns about their reliability in providing accurate medical information.
The implications of these findings extend far beyond the confines of the experimental setting. The researchers found that even a minuscule contamination of 0.01% of the training dataset resulted in 10% of the LLM responses containing incorrect information. Further reduction to 0.001% contamination still led to 7% of the answers being incorrect. This demonstrates the potent impact of even a small number of strategically placed false documents on the internet, underscoring the ease with which malicious actors could potentially manipulate the information ecosystem and influence the output of LLMs.
This vulnerability poses a significant threat to public health, as individuals increasingly rely on online resources and AI-powered tools for medical information. The proliferation of misinformation, amplified by the authoritative appearance of LLM-generated content, could lead to inappropriate self-treatment, delayed medical care, and erosion of trust in established medical practices. The ease with which these models can be manipulated highlights the urgent need for robust safeguards against data poisoning and misinformation campaigns.
While the researchers developed an algorithm to identify and cross-reference medical data within LLMs, they acknowledged the impracticality of comprehensively detecting and removing misinformation from vast public datasets. This emphasizes the critical need for ongoing research into developing more effective methods for identifying and mitigating the impact of data poisoning. The study underscores the importance of a multi-pronged approach, involving collaborative efforts between AI developers, medical professionals, and policymakers, to ensure the responsible development and deployment of LLMs in healthcare and protect the public from the dangers of medical misinformation.
This study serves as a stark warning about the potential for malicious manipulation of LLMs and the subsequent spread of misinformation. The ease with which these powerful tools can be compromised underscores the need for continuous vigilance, robust security measures, and ongoing research to ensure that these technologies are used responsibly and ethically. As LLMs become increasingly integrated into our lives, safeguarding their integrity and protecting the public from the dangers of misinformation remain paramount.
The alarming ease with which even a small percentage of tainted data can skew LLM outputs necessitates proactive measures to combat this vulnerability. While developing algorithms to identify and cross-reference information is a step in the right direction, the vastness and constantly evolving nature of online data make perfect detection an almost insurmountable challenge. This highlights the need for a multi-faceted approach involving continuous monitoring, sophisticated filtering techniques, and collaborations between AI developers, medical professionals, and regulatory bodies.
The implications of this study extend beyond the realm of healthcare. LLMs are increasingly being employed in various sectors, including education, journalism, and legal research. The demonstrated susceptibility of these models to manipulation raises concerns about the potential for spreading misinformation across multiple domains, impacting public discourse, and eroding trust in information sources. Therefore, addressing the vulnerability to data poisoning is crucial for ensuring the responsible and ethical development and deployment of LLMs across various applications.
Further research is urgently needed to develop more sophisticated methods for detecting and mitigating the impact of data poisoning. This includes exploring advanced filtering techniques, incorporating contextual understanding into LLM training, and developing robust fact-checking mechanisms. Equally important is the development of educational initiatives to raise public awareness about the potential for misinformation generated by LLMs and equip individuals with the critical thinking skills to evaluate information sources effectively.
The study highlights the urgent need for regulations and guidelines to govern the development and deployment of LLMs. This includes establishing standards for data integrity, implementing transparency measures, and developing mechanisms for accountability in cases of misinformation. International cooperation is crucial to address this global challenge and ensure that these powerful technologies are used responsibly and ethically.
The NYU Langone Health’s study serves as a wake-up call to the potential dangers of unchecked AI development. While LLMs hold immense promise for various applications, their vulnerability to data poisoning poses a significant threat to information integrity and public trust. Addressing this challenge requires a concerted effort from researchers, developers, policymakers, and the public to ensure that these powerful tools are used to promote knowledge and understanding, rather than becoming vectors for the dissemination of misinformation.
The race is on to develop effective countermeasures against data poisoning, and the future of AI’s positive impact hinges on success in this critical area. Only through a combination of technological advancements, regulatory frameworks, and public awareness can we harness the full potential of LLMs while mitigating the risks they pose to the information ecosystem.



