






A Novel Approach to Combating Misinformation in the Mobile Age: The BERT-LSTM Hybrid Model
The proliferation of misinformation in mobile social networks poses a significant threat to individuals and society. The rapid spread of false or misleading information can have far-reaching consequences, impacting public health, political discourse, and social cohesion. Traditional methods of misinformation detection often struggle to keep pace with the evolving tactics employed by purveyors of fake news. This article explores a novel approach to addressing this challenge: a hybrid model combining Bidirectional Encoder Representations from Transformers (BERT) and Long Short-Term Memory (LSTM) networks. This research investigates the model’s performance, its potential for early-stage detection, and its implications for enhancing digital literacy.
Leveraging the Power of BERT and LSTM for Enhanced Misinformation Detection
The BERT-LSTM hybrid model represents a synergistic fusion of two powerful deep learning architectures. BERT, a transformer-based model, excels at capturing the contextual nuances of language, understanding the subtle relationships between words in a sentence. LSTM networks, on the other hand, are adept at processing sequential data, identifying patterns that emerge over time. By combining these strengths, the hybrid model aims to achieve a more comprehensive understanding of online content, enabling it to discern misinformation from credible information with greater accuracy. This research compares the performance of the BERT-LSTM model with traditional machine learning models like Naive Bayes and Support Vector Machines (SVM), as well as other deep learning architectures, to evaluate its effectiveness in the specific context of mobile social networks.
Early-Stage Detection: Addressing the Challenge of Limited User Engagement Data
Early detection of misinformation is crucial for mitigating its impact. However, traditional detection methods often rely on user engagement metrics such as likes, shares, and comments, which are typically unavailable in the early stages of content propagation. This study investigates the BERT-LSTM model’s ability to detect misinformation based solely on textual content, without relying on user engagement data. The research explores whether the model’s deep linguistic and sequential processing capabilities can compensate for the lack of user feedback, providing a robust solution for early-stage misinformation detection. This capability is particularly important in mobile social networks, where information spreads rapidly and early intervention is essential.
Empowering Users: The BERT-LSTM Model as a Tool for Digital Literacy Education
Beyond its detection capabilities, the BERT-LSTM model holds promise as an educational tool. This research explores the potential of using the model’s insights to enhance digital literacy, empowering users to critically evaluate online content. By understanding how the model identifies misinformation, individuals can gain valuable insights into the linguistic and structural characteristics of false narratives. This knowledge can be translated into educational strategies, training programs, and applications that help users develop critical thinking skills and discern credible information from falsehoods. This focus on user empowerment contributes to a more proactive and informed approach to combating misinformation.
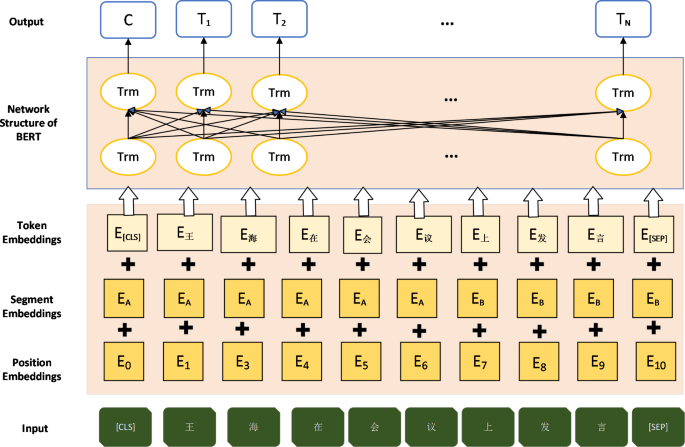
The BERT-LSTM Architecture: A Deep Dive into the Model’s Inner Workings
The BERT-LSTM model operates through a sophisticated pipeline of natural language processing and sequential modeling. Textual data from social media platforms undergoes preprocessing, including tokenization and embedding, before being fed into the BERT layer. BERT’s transformer layers utilize self-attention mechanisms to capture the contextual relationships between words, generating contextualized embeddings. These embeddings are then passed to the LSTM layer, which analyzes the sequential dependencies between tokens, preserving the temporal structure of the text. A fully connected layer and a Softmax layer then process the LSTM’s output, generating a final prediction classifying the content as misinformation or not. This intricate architecture allows the model to analyze text at multiple levels, from individual words to the overall narrative structure.
Data Set Construction and Analysis: A Foundation for Effective Model Training
This research employs a carefully curated dataset specifically designed to address the challenges of misinformation detection in mobile social networks. A custom-developed web crawler collected data from various social media platforms, including Twitter, gathering text, metadata, and multimedia elements. The dataset underwent extensive preprocessing, including data cleaning, feature extraction, and word frequency analysis. This process involved removing irrelevant characters, extracting features like polarity and comment length, and analyzing the frequency of specific words in both English and Chinese text. The resulting dataset provides a rich and diverse foundation for training the BERT-LSTM model, enhancing its ability to detect misinformation in real-world scenarios. The research also acknowledges the limitations of the dataset size and its potential impact on the generalizability of the findings.
The results of this research contribute valuable insights into the fight against misinformation in mobile social networks, offering a powerful new tool for detection and a potential pathway for enhancing digital literacy. The BERT-LSTM hybrid model’s ability to combine contextual and sequential analysis holds significant promise for improving the accuracy and speed of misinformation detection, particularly in the crucial early stages of propagation. Furthermore, its potential as an educational tool could empower individuals to become more discerning consumers of online information, fostering a more resilient and informed online community. Further research and development in this area could lead to even more sophisticated and effective strategies for combating the pervasive challenge of misinformation.



