






Unmasking Deception: A Novel Approach to Fake News Detection Using Adversarial Training and Transformer Models
In today’s interconnected world, the rapid dissemination of information through online platforms has made it increasingly challenging to distinguish between credible news and fabricated stories. The proliferation of fake news poses a significant threat to democratic processes, public trust, and social harmony. To combat this menace, researchers are constantly exploring innovative techniques to detect and mitigate the spread of misinformation. This article delves into a groundbreaking study that utilizes state-of-the-art word embedding techniques and adversarial training to enhance the accuracy of fake news detection models.
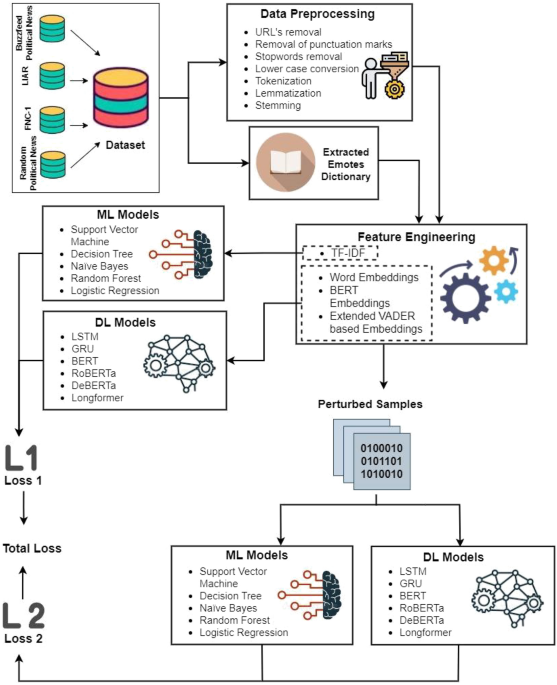
The study employed four publicly available datasets, each containing a diverse collection of political news articles, online posts, and reports: the Random Political News dataset, the Buzzfeed Political News dataset, the LIAR dataset, and the FNC-1 dataset. These datasets vary in size and content, providing a comprehensive platform to evaluate the performance of different fake news detection models.
The research explored various word embedding techniques to capture the nuances of language and meaning within the datasets. Term Frequency-Inverse Document Frequency (TF-IDF) identified keywords indicative of fake news, while Word2Vec embeddings uncovered semantic relationships between terms. BERT embeddings provided contextualized word representations, enabling a deeper understanding of complex linguistic structures. Finally, an Extended VADER lexicon analyzed the sentiment orientation of news content, capturing emotional cues that often signal deceptive or inflammatory narratives. These diverse embedding methods allowed the models to analyze the text from multiple perspectives, enhancing their ability to discern fake news from credible sources.
The experimental setup included a rigorous five-step process executed on Google Colab Pro Plus. The datasets were split into training and testing sets, employing an 80:20 ratio. Deep learning and transformer algorithms were trained extensively for 70 epochs with early stopping criteria. A critical aspect of this study was the incorporation of adversarial training. Models were trained initially on the original datasets and subsequently on datasets augmented with perturbed samples generated using the Fast Gradient Sign Method (FGSM). This method intentionally introduces small perturbations to the input data, forcing the model to learn more robust features and become less susceptible to adversarial attacks.
The study evaluated model performance using standard metrics: precision, recall, F1-score, and accuracy. Precision measured the accuracy of positive predictions, while recall assessed the model’s ability to correctly identify all positive instances. The F1-score combined precision and recall into a single metric, providing a balanced assessment of overall performance. Accuracy measured the proportion of correctly classified instances.
Before adversarial training, the models exhibited promising results. On the Random Political News dataset, traditional machine learning models like Random Forest achieved accuracy up to 90.7%. Transformer-based models like BERT performed even better, reaching an accuracy of 92.43%. Similar trends were observed across the other datasets, with transformer models consistently outperforming traditional approaches.
The introduction of adversarial training significantly boosted the models’ resilience and performance. On the Random Political News dataset, the accuracy of BERT improved from 92.43% to 93.43%. Similarly, notable improvements were observed across all datasets and models, demonstrating the efficacy of adversarial training in enhancing robustness and generalization. The greatest improvement was seen with the FNC-1 dataset, where models like Longformer achieved an accuracy increase of up to 14% after adversarial training. This underlines the importance of preparing models for real-world scenarios where data may be manipulated or incomplete.
The study’s findings highlight the effectiveness of combining advanced word embedding techniques with adversarial training for fake news detection. The results consistently demonstrate the superior performance of transformer models, particularly BERT, when compared to traditional machine learning approaches. The incorporation of adversarial training further strengthens these models, making them more robust and capable of handling noisy or manipulated data.
A comparative analysis with previous studies demonstrates the significant advancements achieved in this research. The proposed framework, utilizing BERT with adversarial training, outperformed existing methods on three out of the four datasets, setting a new benchmark for fake news detection accuracy. This research provides a compelling case for the adoption of transformer models and adversarial training in the ongoing fight against misinformation. The developed models offer a powerful tool for identifying and flagging potentially deceptive news content, empowering individuals and organizations to make informed decisions based on credible information. Future research can build upon these findings by exploring other adversarial training techniques and investigating the application of these methods to other domains and languages. The continued development of sophisticated fake news detection models is crucial to safeguarding the integrity of information and fostering a more informed and responsible digital society.



